分布式锁使用的场景
在分布式场景出现如果多个线程同时去对数据进行操作容易造成数据错乱。比如:
A服务、B服务、C服务,三个服务同一时间对数据库进行减操作,这时候相当于单服务中的多线程操作同一资源类
需要保证资源的原子性,原子性就需要通过锁来进行处理。这里的锁不能是jdk里面提供的本地锁,因为这的三个线程是来源 与不同的服务器,所以需要引入一个共享的信息来进行锁的标识,这里就以redis作为分布式资源标识。
在了解分布式环境下保持数据一致性之前我们先了解一下单机环境下并发如果保持数据一致性的。
一:单机环境高并发保持数据一致性
并发情况下保持数据一致性更多的情况下是加锁。
1.synchronized锁
1 | private synchronized String selectDb() { |
直接锁住整个方法,保证资源被按顺执行,确定锁住整个方法效率低下。
优化的方法可改为分段锁,即在方法里对核心业务的操作进行锁处理,如下:
1 | //本地锁加锁 |
2.Lock锁
1 | private String selectD2b() { |
3.使用JUC下面的atomic
二:分布式环境保持数据一致性
这里使用redis技术作为实现分布式锁
1.原理redis的 setnx k,v原理实现分布式锁。如下
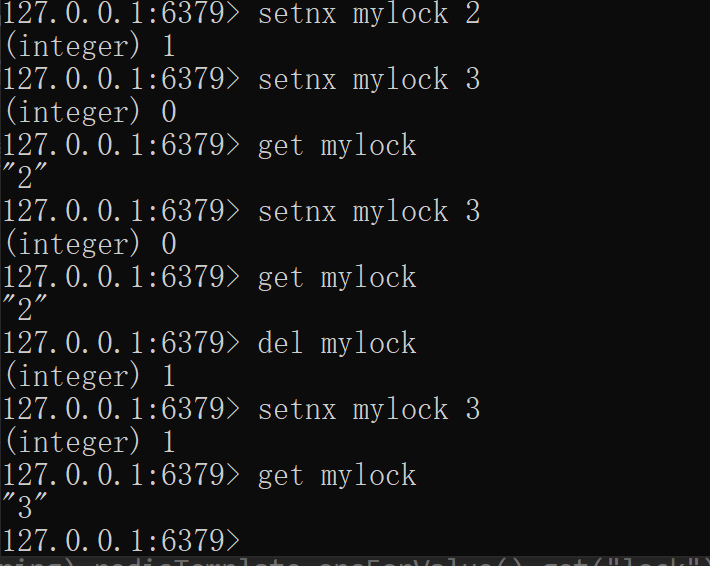
上图可以看出,我们第一步setnx mylock 2返回了1表示成功,当我再次使用同样的key mylock去设置值3时
返回0表示失败,这一步就可以是占坑,简单的理解就是这个Key已经在使用了,其他人想要使用不可以,必须等待这个key被释放(del掉)其他的人才能使用。下面剩余的步骤可以很好的展现出来
上面是他们的原理,那么我在java代码怎么实现呢?以及实现时存在的坑点。
代码如下:
1 |
|
使用reids实现分布式锁坑点讲解:
1.在使用setnx k,y和设置k过期时间时必须要保持其原子性
redisTemplate.opsForValue().setIfAbsent(“lock”, uuid, 30, TimeUnit.SECONDS);
为什么?防止死锁。
如果setnx k,v和设置过期时间分开设定的话,前面的setnx k,v执行完后假如redis挂掉或者服务器down掉,那么这个时候的k是没有过期时间的,导致了后面的线程会一直占用不到坑,从而不能进去执行业务功能。
2.v值必须唯一,作用防止后面的删除操作错删。
导致原因:我们在占坑的时候会给这个坑一个失效时间,假如失效时间为30s,但是这个业务A由于其他原因执行40s,那么此时这A线程的坑位已经释放了,此时后面进来的B线程成功占坑,因为他们的坑位k值是一样的,如果直接用k去删除的话,那么肯定会出现问题。
因为我后面来的B业务还没做完,你前面的延迟完成A业务的程序把我的坑位给释放了,所以在删除的key的时候,会先取key里面的v值和自己的v值对比如果一样就删除。不一样表示做其他措施处理。
3.坑位的释放(key的删除)也必须要保持原子性道理和上面的1一样
4.最棘手的问题还是业务续期的问题,自行处理起来很难处理。如坑位的过期时间为30s,业务的执行时间不一定时30s内处理完的。
在redssion框架没有出来之前,上面的原子性保证都是通过lua脚本语言来处理的,而关于业务雨业务需求的功能都是各自公司自行处理。
redisson的诞生很好的解决了上面的各类问题,使用起来也非常的简单:
redssion分布式锁
1 |
|