前言
之所以写这篇基础语句文章,主要是因为前段时间在接触一些比较复杂的数据语法操作时,发现自己对这方面的知识还是有些欠缺的,希望这篇初级语句文章对自己以后的职业生涯有所帮助。
本文摘自:https://juejin.im/entry/591427a22f301e006b861726
insert into 语句
insert into用于向数据表中插入数据。对于标准的SQL语句而言,每次只能插入一条记录。insert into语法格式如下:
1 |
|
执行插入操作时,表名后可以用括号列出所有需要插入值的列名,而value后用括号列出对应需要插入的值。 例如:
1 |
|
如果不想在表后用括号列出所有列,则需要为所有列指定值;如果某列的值不能确定,则为该列分配一个null值
1 |
|
然而此时,Pigeau记录的主键列的值是2,而不是SQL语句插入的null,因为该主键列是自增长,系统会自动为该列分配值
根据外键约束规则:外键列里的值必须是被参照列里已有的值,所以向从表中插入记录之前,通常应该先向主表中插入记录,否则从表记录的外键列只能为null。现向从表student_table2中插入记录
在一些特殊的情况下,我们可以使用带子查询的插入语句,带子查询的插入语句可以一次插入多条记录
1 |
|
update语句
update语句用于修改数据表的记录,每次可以修改多条记录,通过使用where子句限定修改哪些记录。没有where子句则意味着where表达式的值总是true,即该表的所有记录都会被修改,update语句的语法格式如下:
1 |
|
delete from 语句
delete from语句用于删除指定数据表的记录。使用delete from语句删除时不需要指定列名,因为总是整行地删除。使用delete from语句可以一次删除多行,删除哪些行采用where字句限定,只删除满足where条件的记录。没有where字句限定将会把表里的全部记录删除
delete from语句的语法格式如下:
1 |
|
当主表记录被从表记录参照时,主表记录不能被删除,只有先将从表中参照主表记录的所有记录全部删除后,才可删除主表记录。还有一种情况,定义外键约束时定义了主表记录和从表记录之间的联级删除on delete cascade,或者使用on delete null用于指定当主表记录被删除时,从表中参照该记录的从表记录把外键列的值设为null
单表查询
select语句的功能就是查询数据。select语句也是SQL语句中功能最丰富的语句,select语句不仅可以执行单表查询,而且可以执行多表连接查询,还可以进行子查询,select语句用于从一个或多个数据表中选出特定行、特定列的交集
单表查询的select语句的语法如下:
1 |
|
当使用select语句进行查询时,还可以在select语句中使用算术运算符(+、-、*、/),从而形成算术表达式:使用算术表达式的规则如下
- 对数值型数据列、变量、常量可以使用算术运算符(+、-、*、/) 创建表达式
- 对日期型数据列、变量、常量可以使用部分算术运算符(+、-、)创建表达式,两个日期之间可以进行减法运算,日期和数值之间可以进行加、减运算
- 运算符不仅可以在列和常量、变量之间进行运算,也可以在两列之间进行运算
下面的select语句中使用了算术运算符
1 |
|
SQL语言中算术符的优先级与java语言的运算符优先级完全相同,MySQL使用concat函数来进行字符串连接运算。
1 |
|
对于MySQL而言,如果在算术表达式中使用null,将会导致整个算术表达式的返回值为null;如果在字符串连接运算符中出现null,将会导致连接后的结果也是null
1 |
|
select默认会把所有符合条件的记录全部选出来,即使两行记录完全一样。如果想去除重复行,则可以使用distinct关键字从查询结果中清除重复行,比较下面两条SQL语句的执行结果:
1 |
|
注:使用distinct去除重复行时,distinct紧跟select关键字,它的作用是去除后面字段组合的重复值,而不管对应对应记录在数据库是否重复
前面已经看到了where字句的作用:可以控制只选择指定的行。因为where字句里包含的是一个条件表达式,所以可以使用>、>=、<、<=、=和<>等基本的比较运算符。SQL中的比较运算符不仅可以比较数值之间的大小,也可以比较字符串、日期之间的大小
SQL判断两个值是否相等的比较运算符是单等号=,判断不等的运算符是<>;SQL中的赋值运算符不是等号,而是冒号等号(:=)
SQL支持的特殊比较运算符
| 运算符 | 含义 |
|---|---|
| expr1 between expr2 and expr3 | 要求expr1 >= expr2 并且 expr2 <= expr3 |
| expr1 in(expr2,expr3,expr4,…) | 要求expr1等于后面括号里任意一个表达式的值 |
| like | 字符串匹配,like后的字符串支持通配符 |
| is null | 要求指定值等于null |
下面的SQL语句选出id大于等于2,且小于等于4的所有记录.
1 |
|
使用in比较运算时,必须在in后的括号里列出一个或多个值,它要求指定列必须与in括号里任意一个值相等
1 |
|
与之类似的是,in括号里的值既可以是常量,也可以是变量或者列名
1 |
|
like运算符主要用于进行模糊查询,例如,若要查询名字以“孙”开头的所有记录,这就需要用到迷糊查询,在模糊查询中需要使用like关键字。SQL语句中可以使用两个通配符:下划线(_)和百分号(%),其中下划线可以代表一个任意的字符,百分号可以代表任意多个字符。如下SQL语句将查询出所有学生中名字以”孙”开头的学生
1 |
|
下面的SQL语句将查出名字为两个字符的所有姓名
1 |
|
在某些特殊情况下,查询的条件里需要使用下划线或百分号,不希望SQL把下划线和百分号当成通配符使用,这就需要使用转义字符,MySQL使用反斜线(/)作为转义字符
1 |
|
is null 用于判断某些值是否为空,判断是否为空不能用=null来判断,因为SQL中null=null返回null。如下SQL语句将选择出student_table表中student_name为null的所有记录
1 |
|
如果where字句后面有多个条件需要组合,SQL提供了and和or逻辑运算符来组合2个条件,并提供了not来对逻辑表达式求否,如下SQL语句将选出学生名字为2个字符,且student_id 大于3的所有记录。
1 |
|
下面的SQL语句将选出student_table表中姓名不以下划线开头的所有记录。
1 |
|
SQL中比较运算符、逻辑运算符的优先级
所有比较运算符>not>and>or
order by语句
执行查询后的结果默认按插入顺序排序;如果需要在查询结果按某列值的大小进行排序,则可以使用order by字句
ORDER BY 语句用于根据指定的列对结果集进行排序。ORDER BY 语句默认按照升序对记录进行排序。如果您希望按照降序对记录进行排序,可以使用 DESC 关键字
1 |
|
进行排序时默认按升序排序排列,如果强制按降序排序,则需要在列后使用desc关键字(与之对应的是asc关键字,用不用该关键字的效果完全一样,因为默认是按升序排列)。上面语法中设定排序列时可采用列名、序列名和列别名。如下SQL语句选出student_table表中的所有记录,选出后按java_teacher列的升序排列。
数据库函数
每个数据库都会在标准的SQL基础上扩展一些函数,这些函数用于进行数据处理或复杂计算,他们通常对一组数据进行计算,得到最终需要的输出结果。函数一般都会有一个或者多个输入,这些输入被称为函数的参数,函数内部会对这些参数进行判断和计算,最终只有一个值作为返回值。函数可以出现在SQL语句中的各个位置,比较常用的位置是select之后的where子句中
根据函数对多行数据的处理方式,函数被分为单行函数和多行函数,单行函数对每行输入值单独计算,每行得到一个计算结果返回给用户;多行函数对多行输入值整体计算,最后只会得到一个结果
SQL中的函数和java语言中的方法有点相似,但SQL中的函数是独立的程序单元,也就是说,调用函数时无需使用任何类、对象作为调用者,而是直接执行函数。如下:
多行函数也称为聚集函数、分组函数,主要用于完成一些统计功能,在大部分数据库中基本相同。但不同数据库中的单行函数差别非常大,MySQL中的单行函数具有如下特征
- 单行函数的参数可以是变量、常数或数据列。单行函数可以接收多个参数,但只返回一个值
- 单行函数会对每行单独起作用,每行(可能包括多个参数)返回一个结果
- 使用单行函数可以改变参数的数据类型。单行函数支持嵌套使用,即内层函数的返回值是外层函数的参数
MySQL的单行函数分类如图所示
MySQ数据库的数据类型大致分为数值型、字符型、和日期时间型。所以mysql分别提供了对应的函数。转换函数主要负责完成类型转换,其他函数又大致分为如下几类
- 位函数
- 流程控制函数
- 加密解密函数
- 信息函数
1 |
|
MySQL提供了如下几个处理null的函数
- ifnull(expr1, expr2):如果expr1为null,则返回expr2,否则返回expr1
- nullif(expr1, expr2):如果expr1和expr2相等,则返回null,否则返回expr1
- if(expr1, expr2, expr3):有点类似于?:三目运算符,如果expr1为true,不等于0,且不等于null,则返回expr2,否则返回expr3
- isnull(expr1):判断expr1是否为null,如果为null则返回true,否则返回false
1 |
|
case函数
case函数,流程控制函数。case函数有两个用法
case函数第一个用法的语法
1 |
|
case函数用value和后面的compare_value1、compare_value2、…依次进行比较,如果value和指定的compare_value1相等,则返回对应的result1,否则返回else后的result
case函数的第二个用法的语法
1 |
|
condition返回boolean值的条件表达式
1 |
|
分组和组函数
组函数也就是前面提到的多行函数,组函数是将一组作为整体计算,每组记录返回一个结果,而不是每条记录返回一个结果
- avg([distinct|all]expr):计算多行expr平均值,其中expr可以是变量、常量或者数据列,但其数据类型必须是数值型。使用distinct表明不计算重复值;all表明需要计算重复值
- count({|[distinct|all] expr}):计算多行expr的总条数,其中expr可以是变量、常量或者数据列,但其数据类型必须是数值型。用星号()表示统计该表内的记录行数
- max(expr):计算多行expr的最大值
- min(expr):计算多行expr的最小值
- sum([distanct|all]expr):计算多行expr的总和
1 |
|
group by语句
组函数会把所有记录当成一组,为了对记录进行显式分组,可以在select语句后使用group by子句后通常跟一个或多个列名,表明查询结果根据一列或多列进行分组——当一列或多列组合的值完全相同时,系统会把这些记录当成一组
sql group by 语法
1 |
|
如果对多列进行分组,则要求多列的值完全相同才会被当成一组
1 |
|
having语句
如果需要对分组进行过滤,则应该使用having子句,having子句后面也是一个条件表达式,只有满足该条件表达式的分组才会被选出来。having子句和where子句非常容易混淆,它们都有过滤功能,但它们有如下区别
- 不能在where子句中过滤组,where子句仅用于过滤行。过滤组必须使用having子句
- 不能在where子句中使用组函数,having子句才可使用组函数
sql having 语法
1 |
|
多表连接查询
以下book与student数据表:
交叉连接(cross join)
交叉连接无须任何连接条件。返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积
1 |
|
自然连接
自然连接会以两个表中的同名列作为连接条件;如果两个表没有同名列,则自然连接与交叉连接效果完全一样——因为没有连接条件。
1 |
|
在连接条件中使用等于(=)运算符比较被连接列的列值,但它使用选择列表指出查询结果集合中所包括的列,并删除连接表中的重复列
使用using子句的连接
using子句可以指定一列或多列,用于显示指定两个表中的同名列作为连接条件。假设两个表中有超过一列的同名列,如果使用natural join,则会把所有的同名列当成连接条件;使用using子句,就可显示指定使用哪些同名列作为连接条件
1 |
|
使用on子句的连接
最常用的的连接方式,而且每个on子句只指定一个连接条件。这意味着:如果需要进行N表连接,则需要有N-1个join…on对
1 |
|
全外连接或者左、右外链接
这三种外连接分别使用left[outer]join、right[outer]join和full[outer]join,这三种外连接的连接条件一样通过on子句来指定,既可以是等值连接条件,也可以是非等值连接条件
左联接
是以左表为基准,将a.stuid = b.stuid的数据进行连接,然后将左表没有的对应项显示,右表的列为null
1 |
|
右联接和左联接一样:right join on
子查询
子查询就是在查询语句中嵌套另一个查询,子查询可以支持多层嵌套。对于一个普通的查询语句而言,子查询可以出现在两个位置
- form语句后当成数据表,这种用法也被称为行内视图,因为该子查询的实质就是一个临时视图
- where条件后作为过滤条件的值
使用子查询时的注意点
- 子查询要用括号括起来
- 把子查询作为数据表时(出现在from后),可为其起别名,作为前缀来限定数据列时,必须给子查询起别名
- 把子查询作为过滤条件时,将子查询放在比较运算符的右边,可增强查询的可读性
- 把子查询作为过滤条件时,单行子查询使用单行运算符,多行子查询使用多行运算符
1 |
|
listagg函数
oracle的 listagg() WITHIN GROUP () 行转列函数的使用。
即将多行字段数据记录到一行字段中如图:
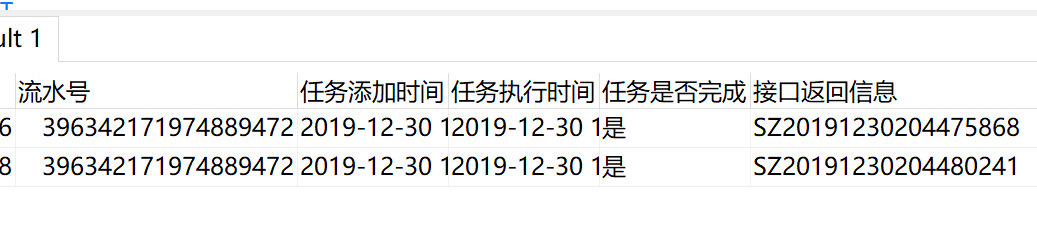
上图有2个相同的流水号,但它们的接口返回信息不同,现有业务需要将同一流水号下的接口返回信息组织在一起,那么就需要使用到此函数:
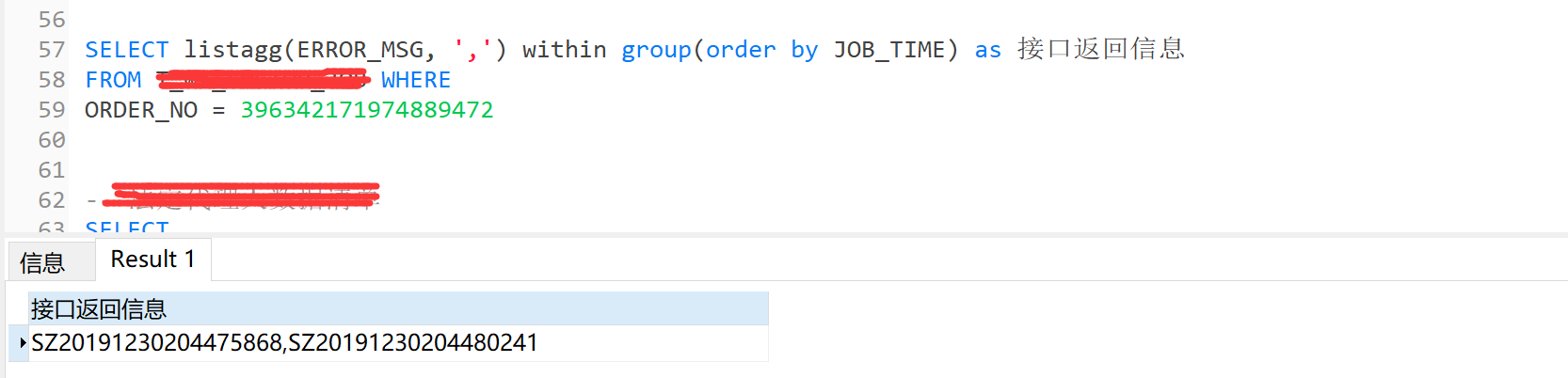
1 |
|
根据表名定位所以在库
1 |
|